
Odstraňování dat v Entity Framework bez preloadu
Tento článek byl napsán v roce 2015. Vývojářské technologie se neustále inovují a článek již nemusí popisovat aktuální stav technologie, ideální řešení a můj současný pohled na dané téma.
Setkal jsem se se zajímavým dotazem ohledně odstraňování dat pomocí Entity Frameworku. Standardní chování EF je totiž takové, že pokud chci data odstranit, musím je nejprve načíst do kontextu. Načítat nicméně hromadu dat, abych je následně odstranil, může být zbytečné.
👨🎓 Nové školení EF Core pro rok 2020
Školení nejnovější verze Entity Framework Core přímo u Vás ve firmě. Naučíte se používat EF Core v celém životním cyklu aplikace od vytvoření modelu, změn v podobě migrací až po dotazování a profilování databázových dotazů.Více o školení Entity Framework Core
Remove
V případě odstranění jednoho záznamu je postup jasný. Nejprve načtu entitu, kterou chci odstranit a poté ji předám do metody Remove().
using (var context = new MyContext())
{
var article = context.Articles.FirstOrDefault(x => x.ArticleId == 1);
context.Articles.Remove(article);
context.SaveChanges();
}
Výsledkem je v tomto případě odeslání SELECTu do databáze následovaným implicitní transakcí, ve které proběhne DELETE. To obvykle není žádná katastrofa (resp.: platíme malou daň za ORM).
RemoveRange
V tomto případě chci odstranit více záznamů. Mohlo by se zdát, že načtením to IQueryable EF jednoduše jen sestaví SQL dotaz, který nakonec po předání do RemoveRange upraví na DELETE.
using (var context = new MyContext())
{
IQueryable<Article> articles = context.Articles.Where(x => x.ArticleId > 0);
context.Articles.RemoveRange(articles);
context.SaveChanges();
}
Tak tomu ale není. Entity Framework data stáhne nejprve do Listu a teprve poté udělá maximum pro to, aby jednotlivé záznamy odstranil. Důvod takové implementace souvisí například s referenční integritou.
public virtual void RemoveRange(IEnumerable entities)
{
List<object> list = entities.Cast<object>().ToList<object>();
this.InternalContext.DetectChanges(false);
foreach (object obj2 in list)
...
V případě velkého objemu dat, může být toto chování nepříjemné. Zase ta daň za ORM. Odstranění 20000 záznamů znamená nejprve 20000 záznamů přednačíst a poté teprve odstranit.
Řešení
Pokud mám nad daty úplnou kontrolu, pak můžu celý mechanismus obejít. Entity Framework se standardně snaží být dostatečně inteligentní a provozuschopný za různých okolností. Neví, že může jen tak odstranit kolekci článků, protože předpokládá, že leckde může být nějaká ta reference. Předcházení problémům pak samozřejmě stojí určitou režii.
Jednoduše pomocí AttachTo
Představme si, že budu mít entitu Article, která může být ještě rozšířena o ArticleDetail. Na výše uvedených příkladech jsem tento vztah nemusel řešit. Entity Framework si všechno sám ohlídal.
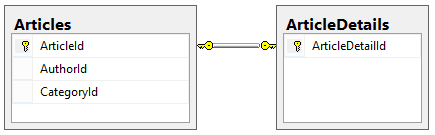
Jeden ze způsobů jak obejít preload před smazáním je použití metody AttachTo nad ObjectContextem.
using (var context = new MyContext())
{
Article article = new Article() { ArticleId = 1 };
context.AsObjectContext().AttachTo("Articles", article);
context.AsObjectContext().DeleteObject(article);
context.SaveChanges();
}
Výsledkem odeslaného dotazu bude nicméně výjimka:
System.Data.SqlClient.SqlException : The DELETE statement conflicted with the REFERENCE constraint "FK_dbo.ArticleDetails_dbo.Articles_ArticleDetailId". The conflict occurred in database "consultancyexamples", table "dbo.ArticleDetails", column 'ArticleDetailId'. The statement has been terminated.
Abych problém s referenční integritou eliminoval, je potřeba explicitně říct EF, že chci ničit i související objekt. Upravím tedy fake entitu article z předchozího příkladu o potřebné informace:
Article article = new Article() { ArticleId = 1, ArticleDetail = new ArticleDetail {ArticleDetailId = 1} };
EF pochopí, že musí nejprve odstranit ArticleDetail a poté samotný Article.
begin transaction with isolation level: ReadCommitted DELETE [dbo].[ArticleDetails] WHERE ([ArticleDetailId] = 1 DELETE [dbo].[Articles] WHERE ([ArticleId] = 1 commit transaction
Samozřejmě kdybych chtěl odstranit větší množství dat, musel bych připojit odpovídající množství objektů a ve všech případech si uhlídat reference.
Po svém pomocí ChangeTrackeru
Další řešení odstraňování dat nabízí ChangeTracker. Sám o sobě je velmi užitečný, pokud bych například chtěl odstraňovat data logicky. Logické odstraňování dat je mnohdy nejrychlejší a nejbezpečnější způsob, jak ve složitých databázových systémech uchovat pořádek.
Pokud zavolám metodu Remove nebo RemoveRange, neprovádí se okamžitě SQL dotaz, ale nejprve se pouze změní stav entit. Při volání SaveChanges metody se teprve kontroluje stav entit a na samotném konci jsou odpalovány nezbytné SQL dotazy proti DB serveru. Metodu SaveChanges můžu přetížit a entity, které jsou označeny ke smazání spravovat vlastním kódem:
public class MyContext : DbContext, IDbContext
{
public override int SaveChanges()
{
foreach (DbEntityEntry entry in ChangeTracker.Entries().Where(p => p.State == EntityState.Deleted))
{
DeleteByMyOwn(entry);
}
return base.SaveChanges();
}
}
Implementace metody DeleteByMyOwn už je na uvážení vývojáře. S typem DbEntityEntry se pracuje velmi dobře a není problém zjistit o jaký typ entity se jedná, jak se jmenuje její primární klíč aj. Dopsat pak lze libovolný SQL dotaz a ten během SaveChanges vykonat (pomocí Database.ExecuteSqlCommand())
Odvážně pomocí ExecuteSqlCommand
Konzervativní řešení samozřejmě nabízí ExecuteSqlCommand. Není pochyb o tom, že se jedná o nejsnazší způsob, který je zároveň i zcela postavený mimo koncept ORM. Na druhou stranu se mi toto řešení velmi často osvědčilo ve chvíli, kdy jsem měl v EF mapování entit M:N a neměl jsem možnost jak efektivně rozpojit vazby.
using (var context = new MyContext())
{
string query = "DELETE FROM AuthorArticles WHERE AuthorId = @AuthorId";
context.Database.ExecuteSqlCommand(query, new SqlParameter("@AuthorId", 4));
}
I v tomto případě je nutné hlídat si vazby a pokud existují závislé objekty, pak provádět hierarchicky odstraňování postupným odstřelováním potřebných dotazů.